ML model Inference flow
In Most of the scenarios, ML/DL (Machine Learning/ Deep Learning) solutions in production use Tensorflow to build their product. Because Tensorflow(TF) has extensive production community support when compared to PyTorch.(However, PyTorch is a go-to choice for ML/DL researchers due to its flexibility)
So let me explain how the data preprocessing should be done:
- Always decouple data Preprocessing component from Model Training/Inferencing Component.
- Use tf.Transform for Preprocessing
I will get back to why tf.Transform ?
1. why do we need to decouple the data preprocessing component from other components in the ML pipeline.?
What is pre-processing in the context of ML ?
“A process of converting raw inputs to features to train the machine learning model”
When you are going to scale your model to serve 10K requests/second. It’s going to be costly to do preprocessing when the architecture is tightly coupled with preprocessing. It’s better to have a separate component for the task of preprocessing and storing features in a suitable storage area like Feast(Feature Store) and those features could be read by the training/serving component.
Our model architecture should be designed in such a way that the transformations/preprocessing carried out during the initial training must be easy to reproduce during the next re-training or while serving/inferencing the model. We can do this by making sure to save the transformations in the model graph or by creating a repository of transformed features.
tf.transform provides an efficient way of carrying out transformations over a preprocessing pass through the data and saving the resulting features and transformation artifacts so that the transformations can be applied by TensorFlow Serving during prediction time.”
2. tf.Transform Implementation
Below are the high-level steps we generally follow as a good practice:
- Create a tf.Transform pre-processing function and pass raw data through it.
- Save TensorFlow Transformation layers
- Load the Transformation layers at the time of model serving
- Pass Inference data through it to get processed features from raw inputs.
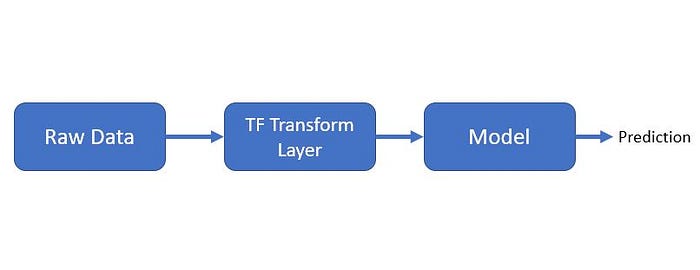
All the tf.Transformations are saved as a TF Graph, and below is how the flow would be like during model serving:
In the tf.Transform documentation you could find almost all the transformations that you might need for your project.
First, we need to create a function that will take raw inputs and then transform them to our needs using the tf.Transform APIs .
Here is an example, we are using scale_to_0_1 which will scale our image pixel tensor values between 0 to 1.
Before we start the training, we pass all our raw data to the above preprocessing_fn then we get the transformed data and transform_layers
Optionally, we could save the transformed_data as TFRecords which could be read by the training component efficiently
At the time of model serving, we will load the tf.Transform layers.
This is how the model serving flow will look like:


Model Serving flow
We pass the raw inputs to the transform layer then we get features of the given input, then we pass those features to the model for prediction.